
Para conseguir una reducción tan espectacular de la cantidad de bits necesarios para transmitir una señal de audio MP· utiliza diferentes técnicas. Entre estas técnicas están las basadas en codificación perceptual y otras como reserva de bytes, ensamblado de stereo o codigos Huffman. La codificación percetual consiste en eliminar toda la información que va en la señal de audio que el oido humano no es capaz de detectar. A continuación pasamos a describirlas:
CODIFICACIÓN PERCEPTUAL
Umbral mínimo de audición El umbral mínimo de audición del oido es la potencia por debajo de la cual un tono a una frecuencia dada no es capaz de ser detectado por el oido. Este umbral es no-lineal. Como vemos en la figura, que representa la ley de Fletcher y Mundson, las frecuencias en las que mejor oimos son las que estan entre los 2 y los 5 Khz. Por lo tanto frecuencias fuera de esa banda no son totalmente imprescindibles ya que apenas serán percibidas. Por lo tanto es posible eliminar el contenido de la señal de audio fuera de estas frecuencias.
Como podemos apreciar en el dibujo el rango en el que hace falta una menor potencia para que el tono sea escuchado es entre los 2 y los 4 Khz.
El efecto de enmascaramiento Este efecto consiste en que, cuando en una señal de audio existe un tono a una frecuencia dada, produce un efecto de enmascaramiento en las frecuencias cercanas a ella, de manera que si en estas fercuencias cercanas la señal no supera un determinado umbral de potencia no podrán ser escuchadas y, por lo tanto, no será necesario codificarlas. La forma que tomará este umbral de potencia según la posición del tono o de los tonos enmascaradores es lo que se llama modelo psicoacústico, que como el propio nombre indica es un modelo de percepción que trata de emular la percepción del oido humano.

En esta gráfica podemos ver cómo si ponemos un tono a 1 Khz de 60 dB (tono enmascarador) y luego ponemos otro tono a, por ejemplo 1,1 Khz y variamos la frecuencia de este, no es posible detectar la presencia de este segundo tono hasta que su potencia supere el umbral presentado en la figura.
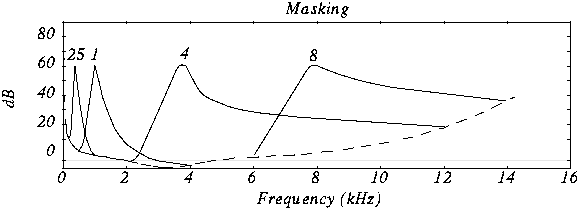
En este caso vemos varios tonos enmascaradores y los nuevos umbrales de audición resultantes. En MP3 lo que se hace es dividir el espectro que se va a transmitir (es decir entre los 2 y los 5 Khz) en subbandas de frecuencia, de manera que se evalua la potencia de la subbanda y se crea el umbral de enmascaramiento en la subbandas cercanas. Las subbandas cercanas que superen ese umbral de potencia son codificadas y las que no lo superen no son codificadas.

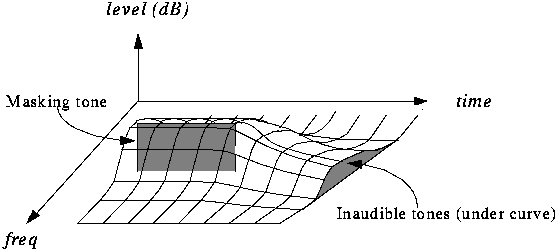
Además el enmascaramiento no sólo es en frecencia sino también en el tiempo como podemos apreciar en la figura.
La reserva de bytes: A menudo, algunos pasages de una pieza musical no pueden ser codificados a una misma tasa sin alterar la calidad de la musica. MP· usa entonces una pequeña reserva de bytes que actua como un buffer usando la capacidad de pasages que pueden ser codificados a una tasa inferior en el flujo dado.
El ensamblado de stereo En el caso de una señal stereofónica, el formato MP3 puede usar algunas herramientas mas, para conseguir comprimir más aun los datos.
Intensity stereo(IS) El oido humano no es capaz de localizar con total certeza el origen espacial de sonidos para frecuencias muy altas o muy bajas. Esta técnica aprovecho esto, grabando algunas frecuencias como una señal monofónica, de manera que se resta al sonido un mínimo de contenido espacial.
Mid/Side(M/S) Stereo Cuando los canales izquierdo y derecho son similares entonces se crea un canal medio (L+R) y un canal lateral (L-R), que son codificados en lugar de codificar el canal izquierdo por un lado y el derecho por otro. De esta forma se consigue reducir los datos transmitidos utilizando menos bits para el canal lateral. Después durante la reproducción el decodificador MP3 reconstruirá los canales izquierdo y derecho.
Codificación Huffman: Esta técnica de codificación se usa al final de todo el proceso. Actua creando códigos de longitud variable, de manera que los símbolos que aparecen en el flujo de bits con más probabilidad tienen códigos mas cortos. La traducción entre símbolos y códigos se realiza mediante una tabla. Cada código tiene un único prefijo de manera que los códigos pueden ser decodificados correctamente a pesar de su longitud variable. Este tipo de codificación permite de media reducir un 20% la cantidad de datos a transmitir. Es un complemento ideal para la codificación perceptualya que, durante las grandes polifonías, la codofocación perceptual es muy eficiente ya que muchos sonidos son enmascarados, pero sin embargo poca información es idéntica y el algoritmo de Huffman se hace ineficiente.Durante los sonidos puros hay pocos efectos de enmascaramiento, pero la codificación Huffman se hace muy eficiente ya que el sonido digitalizado contiene muchos bytes repetidos.
El siguiente ejemplo ilustra en que se basa la codificación Huffman.
The Shannon-Fano Algorithm
Symbol A B C D E
----------------------------------
Count 15 7 6 6 5
Arriba vemos el símbolo y abajo el numero de veces que ha salido. A continuación codificamos los símbolos colocandolos en un árbol por orden de probabilidad.
Symbol Count log(1/p) Code Subtotal (# of bits)
------ ----- -------- --------- --------------------
A 15 1.38 00 30
B 7 2.48 01 14
C 6 2.70 10 12
D 6 2.70 110 18
E 5 2.96 111 15
TOTAL (# of bits): 89
Con la codificación elegida en el árbol nos sale la siguiente tabla donde log(1/p) muestra el logaritmo en base dos del inverso de la probabilidad de aparición del símbolo, que representa la cantidad de información contenida en el símbolo, es decir, el nº de bits necesarios para codificarlo.
La codificación Huffman es
bastante parecida a lo anterior. Simplemente construimos el
árbol de la manera presentada en la figura, teniendo en cuenta
las frecuencias de aparición de cada uno de los símbolos.
Symbol Count log(1/p) Code Subtotal (# of bits)
------ ----- -------- --------- --------------------
A 15 1.38 0 15
B 7 2.48 100 21
C 6 2.70 101 18
D 6 2.70 110 18
E 5 2.96 111 15
TOTAL (# de bits): 87
En la transmisión de los códogos se da que el prefijo de cada código es único de manera que no se puede confundir con el resto.
entropy = (15 x 1.38 + 7 x 2.48 + 6 x 2.7 + 6 x 2.7 + 5 x 2.96) / 39
= 85.26 / 39 = 2.19
87 / 39 =
2.23 bits por simbolo