![]()
TARJETAS DE AUDIO - HARDWARE
![]()
ENTRADAS Y SALIDAS. TIPOS DE CONECTORES
Las entradas de una tarjeta de audio son conectores eléctricos u ópticos que pueden ser de tipo digital o analógico. Los más básicos son:

Tradicionalmente, para las E/S anteriores se han utilizado conectores mini-jack como los que usamos en un walkman, por ejemplo. Éstos siguen siendo los más comunes en las soluciones de nivel bajo y medio. Se trata de conexiones analógicas de media calidad. Algunas tarjetas incorporan también conectores tipo RCA. Normalmente cada RCA es un canal independiente (mientras que en el jack van dos canales juntos). Por ello siempre van de dos en dos (clásicamente el rojo es el canal derecho y el blanco el izquierdo). Ofrecen mayor calidad que los conectores jack tradicionales pero son más caros y menos compactos.

Otras conexiones son:
Además de las anteriores conexiones, que son externas, las hay también internas, siendo la más importante la que va del CD-ROM a la tarjeta de sonido, para poder escuchar los CD’s de música. Puede ser digital (sólo en los más modernos) o analógica, de la cual hace tiempo había varios formatos (para CD-ROMs Sony, Mitsumi, IDE...) y que ahora ya están unificados. Incluso en algunas tarjetas antiguas se incluía un conector IDE de 40 pines para el CD-ROM (cuando los CD-ROMs eran algo extra y no existía el EIDE con sus 2 canales).
Las tarjetas de sonido administran sus canales de salida para conseguir diferentes mejoras en la reproducción de audio, y es interesante hacer aquí un recorrido histórico de los diversos métodos desde el sonido monoaural a los últimos avances de sonido 3D envolvente. Un factor importante para comprender el funcionamiento de las tarjetas de audio es el de canal y su relación con la reproducción de la música procesada por la tarjeta. Podríamos explicar el concepto de canal de forma sencilla como una pista de sonido diferente para cada altavoz en la que estarán grabados los datos que debe reproducir, de forma que a cada altavoz le llega una señal distinta. Así cada altavoz reproducirá el sonido que le corresponde, lo cual, administrado de forma adecuada logrará el deseado realismo.
Cuando apareció la entonces revolucionaria AdLib, era capaz de reproducir el sonido por un canal, o sea, hablamos de sonido monoaural en su sentido más estricto. Cuando escuchamos el sonido estéreo, nos llega mediante dos canales, el izquierdo y el derecho, mejorando mucho el realismo del sonido.
Pero llegó un momento en que esto pareció ser poco, y se desató la fiebre 3D. Se pensó que no tenía sentido que el sonido estuviese siempre delante de nosotros y que era mejor que nos rodeara. Esto es lo que van a intentar reproducir los Dolby Surround, AC-3, A3D, THX, DirectSound3D... (hay multitud de sistemas para producir sonido envolvente). Algunas tarjetas de sonido dicen ser capaces de producir sonido 3D con tan sólo dos altavoces. Estos sistemas, más que sonido envolvente, crean "sonido extraño", pues combinan los dos canales del estéreo para provocar sensación de profundidad en sonido (nunca sonido "envolvente"). Últimamente, además de los dos altavoces tradicionales, los vendedores ofrecen un subwoofer. Este altavoz se utiliza principalmente para la reproducción de los sonidos más graves, pero seguiremos teniendo solamente dos canales.
Otros utilizan cuatro altavoces, en tarjetas de sonido cuadrofónicas. Éstas tienen dos salidas estéreo, para dos pares de altavoces (un total de cuatro). La calidad obtenida es bastante buena, ya que, además de los cuatro altavoces que hacen que percibamos el sonido desde cualquier dirección, las tarjetas más modernas incorporan software que permite la calibración de nuestra posición con respecto a los altavoces, ajustando automáticamente el volumen para que el sonido se "centre" en nuestra cabeza (si un altavoz está más lejos de nosotros que el otro y por los dos emitimos el mismo volumen, el sonido lo notaremos desplazado; habremos de ajustar el volumen de cada altavoz para escuchar el sonido lo más centrado posible).

Sistemas más avanzados aportan, al igual que ocurría con los sistemas de dos altavoces, un subwoofer junto con los cuatro altavoces, consiguiendo un mayor realismo en el sonido envolvente. Ya existen diversas soluciones (como el Creative FPS 2000) que por un precio económico proporcionan sonido cuadrafónico con cuatro altavoces y un subwoofer.
Una curiosa apuesta hacia el ahorro son los altavoces USB. En ellos se envian los datos digitales por el puerto USB y los altavoces se encargan de reproducir el sonido. No hay complicaciones y la calidad de reproducción es bastante elevada. Además todas esas soluciones (como la de Philips o Microsoft) también llegan con un Subwoofer, por lo que su calidad de reproducción es bastante elevada. Pero su mayor ventaja es también su mayor contrapartida. Al no incluir ni necesitar tarjeta de sonido, no hay forma de grabar nada. También hay que decir que de momento el precio no es uno de sus mayores fuertes, comparados con altavoces convencionales de buena calidad, con soluciones de dos, tres (dos más subwoofer), cinco (cuatro más subwoofer) o seis (Dolby Digital) altavoces.
También como altavoces convencionales podemos incluir a los monitores con altavoces incorporados, los cuales poseen una calidad de sonido sólo aceptable.
Conversión de analógico a digital
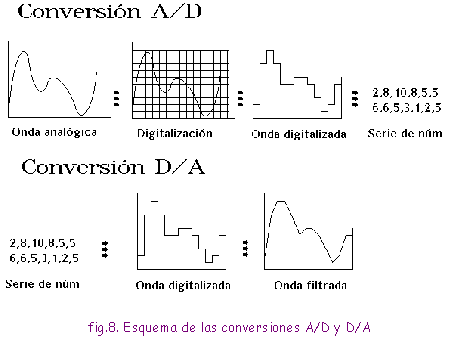
La señal de audio que obtiene un micrófono es analógica. El proceso para digitalizar la onda analógica se inicia con la toma de muestras periódicas de la misma (muestreo), para después asignar a cada muestra un cierto valor numérico de entre un conjunto finito (cuantificación). Este proceso de muestreo y cuantificación permite que los sonidos puedan ser procesados utilizando el lenguaje binario de las computadoras. Además los unos y ceros son facilmente almacenables según la presencia o la ausencia de algo: carga eléctrica (memorias RAM), magnetismo (discos duros) o agujeros (CD).
La frecuencia de muestreo o sampling rate es el número de muestras de la señal que se recogen cada segundo. Si cogemos muestras mas a menudo, la calidad del sonido será mayor, pero, también aumenta el espacio que ocupa la toma en bits. Esta frecuencia de muestreo limita la frecuencia maxima que podremos recoger de la señal. En virtud del teorema de Nyquist, la frecuencia de muestreo debe ser como mínimo el doble de la máxima componente en frecuencia de la señal que queremos registrar, para evitar el fenómeno de aliasing (solapamiento de espectros).

Dado que en este caso tratamos con señales de audio, tenemos que tener en cuenta el rango de frecuencias que el oído humano es capaz de captar para muestrear a una frecuencia adecuada para que nuestro oído no aprecie que el sonido ha sido "filtrado", y a la vez no sobremuestrear la señal y que una vez digitalizada ocupe demasiado espacio. El oído humano, genéricamente, puede escuchar sonidos de entre 20 Hz y 20 KHz. Por ello, la frecuencia de muestreo que se asignó a los CD-audio es de 44'1 KHz, algo mas del doble de la máxima que podemos captar, con lo cual se cumple el teorema de Nyquist y tenemos una calidad más que suficiente. Algunas de las frecuencias de muestreo utilizadas en sistemas de grabación y comunicación de voz son:
|
DAT |
48.000 Hz |
|
CD-audio |
44.100 Hz |
|
Telefonia |
8.000 Hz |
Como ya hemos dicho, las muestras analógicas, que toman valores de un conjunto contínuo, se transforman en muestras digitales, que toman el valor más cercano de un conjunto discreto de L niveles. Cuanto mayor sea este número de niveles, más aproximado será el valor discreto al original. En la figura 7 se muestra una función que representa un cuantificador uniforme de L=7 niveles.

Cada uno de estos L niveles se representa mediante una secuencia de n bits (llamados bits de profundidad), de forma que L=2n. Por tanto, cuanto mayor sea el número de niveles, más bits necesitaremos para realizar la cuantificación, y más espacio ocupará nuestra señal digitalizada.
Hay distintas tecnologías para llevar a cabo esta cuantificación, pudiéndose utilizar el concepto de comparar uno a uno y en orden con los valores cuantificados, o bien comparadores de voltaje con cada uno de los pesos de los bits, lo cual es una forma de llegar más rápidamente al valor de voltaje que buscamos (dado que lo más común en las señales de audio es codificarlas con 16 bits, en el primer caso tardaríamos un máximo de 216 pasos, mientras que en el segundo solo 16).
Todo este proceso de muestreo y cuantificación de muestras se denomina PCM (Pulse Amplitude Modulation).
Conversión de digital a analógico
El propósito de un conversor digital-analógico es, a partir de los valores numéricos codificados bits, reproducir la forma de onda continua que representan esos valores. Hay dos modos principales de obtener una señal analógica a partir de datos PCM. Uno es controlar las corrientes que indican los bits y sumarlas pesadas por el valor binario de la posición que ocupa el bit. El otro consiste en controlar (pesando binariamente el tiempo en función de la señal) los momentos en que una corriente fija pasa por un integrador. Para el primer método necesitaremos cuatro generadores de corriente y un sumador; para el segundo, un solo generador de corriente y un integrador.
Lógicamente -y esto vale también para el caso de la conversión A/D- por la complejidad de las señales de audio, ninguno de los métodos se usa con la simplicidad indicada aquí, sino que hay que tener en cuenta muchos otros factores para lograr una correcta transformación. A modo de resumen, presentamos de forma simplificada las conversiones que acabamos de explicar en la figura 8.
Como ya vimos antes, este Procesador de Sonido Digital libera de trabajo al procesador central del equipo. Para estudiarlo con algo más de profundidad, conviene primero de todo distinguir tres conceptos parecidos que usan prácticamente las mismas glas y que son por tanto susceptibles de confusión.
En primer lugar tenemos la tecnología general de los DSP (en su acepción de Procesadores Digitales de Señal), que ha revolucionado el panorama del procesamiento de señales digitales. Estos DSP son poderosos microprocesadores capaces de procesar mucha información en tiempo real como señales de radio, sonido o vídeo.
En el contexto de los anteriores es en el que se enmarcan los DSP (Procesadores de Sonido Digital) que se aplican sobre una señal sonora.
Pero también tenemos el DSP como Procesamiento Digital de Campos Sonoros, que se trata de una tecnología creada por Yamaha en 1986 para recrear las mismas características acústicas de una sala de conciertos, un club de jazz o de una sala cinematográfica en nuestro propio hogar.
El DSP que nos interesa ahora es el que se refiere al sonido. Cuando tratamos con una pista de sonido que tenemos grabada, por ejemplo, podemos tener la posibilidad de aplicarle efectos (eco, coro, reverberación,...) o también simular sintetizadores de sonido, realizar fades, ... Por supuesto, este proceso de modificación de una señal digital requiere potencia de cálculo, y además existen multitud de aplicaciones en la que se hace necesario el procesado de un efecto en tiempo real. Es por ello que actualmente, tanto las tarjetas de gama baja como las de gama alta incorporan un DSP, diseñado específicamente para éste tipo de tareas con lo cuál se consigue, además de liberar de carga al procesador del PC, un mayor rendimiento, ya que éste último no deja de ser una máquina de propósito general, y puede resultar menos capaz para estos procesos.
Con el continuo desarrollo de los avances en tecnología digital, el DSP se ha convertido en la parte principal de cualquier tarjeta de sonido, y entre las especificaciones de cualquier tarjeta comercial, incluso de gama más baja podemos encontrar funciones como:
Aunque el sintetizador de sonidos podría considerarse desde el punto de vista de la arquitectura lógica de una tarjeta de sonido como una parte distinta del DSP, lo cierto es que en muchas tarjetas ambas funciones –el procesado de la señal de audio y la síntesis de sonidos- lo realiza el mismo chip. La compañía E-mu Systems®, Inc. aparece constantemente allí donde se hable de DSP’s para tarjetas de sonido convencionales. Por ejemplo el chip EMU10K1™ es a la vez el "motor de efectos" y el "sintetizador de música" de las tarjetas Sound Blaster y algunos modelos de las tarjetas Maxi Sound, si bien, últimamente otra compañía está entrando fuerte en el mercado: la taiwanesa C-Media Electronics Inc., que ha conseguido que su chip CM7388 esté incorporado en placas madre y tarjetas de sonido de las principales marcas (ver figura 9).

La forma en que éste tipo de chips puede generar (sintetizar) sonido puede basarse en diferentes planteamientos. Del sistema que se elija dependerá en gran medida la calidad del sonido resultante. Veamos 3 tipos de síntesis usados en las tarjetas de sonido:
Síntesis FM (modulación de frecuencia)
Se basa en modular una onda portadora con otra onda moduladora, produciendo así una tercera onda resultado de la modulación. Como este sistema es muy pobre, se usan varios operadores (conjuntos de portadora-moduladora), cada uno de los cuales produce una onda que sirve como portadora o moduladora del siguiente paso. El modo de interconexión de los operadores es denominado algoritmo. Es muy barata, pero no reproduce adecuadamente los sonidos de instrumentos musicales reales. Las guitarras, los metales y sonidos de percusión suenan particularmente mal. Los sintetizadores profesionales que usan este sistema incorporan un gran número de operadores y de algoritmos, pero las tarjetas de sonido de gama media-baja llevan muy pocos como para obtener buenos resultados.
Wavetable (Tabla de Ondas)
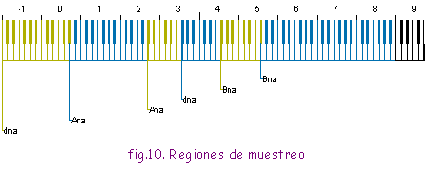
Si grabamos sonidos de instrumentos reales interpretando una nota Do, por ejemplo, y reproducimos esa grabación a mayor velocidad, sonará más agudo. Con las grabaciones de diferentes instrumentos, creamos una Tabla de Ondas, almacenada en memoria ROM o RAM. De la calidad de dichas muestras depende buena parte del resultado sonoro. Es obvio que es importante grabarlas en un estudio de grabación profesional, con buenos instrumentos. Es más cara que la FM, y necesita memoria para almacenar las ondas grabadas. Para conseguir mejor calidad, se usa el multimuestreo, es decir, tomamos varias grabaciones de cada instrumento, por ejemplo, una por cada escala musical (ver figura 10). Esto aumenta la cantidad de memoria necesaria. Sin embargo, para reproducir con fidelidad un sonido no basta con guardar una grabación, ya que cuando se toca una nota diferente, no solo se cambia la frecuencia del sonido, sino otros parámetros importantes (Timbre, etc).
La mayoría de las tarjetas con síntesis por tabla de ondas incluyen cierta cantidad de memoria RAM en la propia tarjeta, o la posibilidad de añadir memoria mediante unos zócalos similares a los de memoria RAM de la placa, para que nosotros podamos grabar nuestras propias muestras y reproducirlas del mismo modo que las predeterminadas en la tarjeta. Además, si tenemos en nuestro equipo una tarjeta que no soporta síntesis por tabla de ondas, es posible en la mayoría de los casos añadir una "tarjeta hija" con las muestras de la tabla de ondas (Wave Blaster, Yamaha, etc.), con lo que conseguiremos la misma calidad musical que en tarjetas superiores, aunque tendremos el inconveniente de no poder aumentar el número de voces simultáneas
Waveguide (Modelado Físico, Síntesis Virtual)
Se basa en simular el sonido de un instrumento musical mediante el cálculo numérico de las ondas de sonido. Es decir, se tienen en cuenta parámetros como la vibración del sonido en un tubo (viento), una cuerda, una membrana (percusión), etc. Pero este proceso se realiza a tiempo real, lo que supone una gran capacidad de cálculo. Es muy cara. De hecho, el primer producto con esta tecnología que salió al mercado (un sintetizador de Yamaha) tenía dentro dos Macintosh Quadra para producir tan sólo 2 notas de polifonía.