III. El reconocedor de habla natural
En general, la capacidad de las máquinas
para percibir su entorno es muy limitada, por lo que la interacción automática
con el medio no es trivial, salvo que las condiciones estén muy controladas
y las señales sean fáciles de interpretar. Sin embargo, la asombrosa facilidad
y rapidez con que los ordenadores realizan operaciones matemáticas, o resuelven
algunas cuestiones tediosas como las de ordenación y búsqueda de información,
hace que las expectativas sobre la capacidad de los mismos para la resolución
de todo tipo de problemas hayan superado y superen, con mucho, a la realidad.
Esto ha hecho que se haya sobrevalorado
la capacidad de los ordenadores, lo que ha llevado, en muchos casos, a un análisis
simplista y, por tanto, a la subestimación de problemas complejos como el reconocimiento
de voz, la inteligencia artificial, etc.
En general, se podría decir que los
ordenadores actuales automatizan satisfactoriamente muchas tareas que, para
una persona, son difíciles, repetitivas o requieren mucho tiempo, mientras que
se muestran más torpes para resolver tareas aparentemente sencillas como leer
caracteres escritos a mano, reconocer voz o identificar una imagen. Esto se
debe, por ejemplo, a que para hacer reconocimiento de voz, hay que pasar de
las tareas relativamente sencillas de detección o medición de señales, ordenación,
búsqueda de información y realización de cálculos matemáticos, a la labor de
interpretación de los datos, que requiere
de procesos complejos de razonamiento, de capacidad de aprendizaje y de bases
de conocimiento. Una dificultad añadida a la resolución de este tipo de problemas
es que no se conocen los mecanismos que nos permiten percibir el entorno, a
pesar de que la percepción es algo que experimentamos todos los seres vivos.
Si bien todo lo dicho en los párrafos
anteriores es cierto, también lo es que los avances realizados en los más de
cincuenta años de investigación en reconocimiento de voz, junto con los avances
en el campo de la informática, han hecho posible la resolución de muchas cuestiones
que hace tan solo unos años pertenecían al mundo de la ciencia-ficción. Este
hecho ha desencadenado la proliferación de productos y servicios nuevos basados
en tecnologías del habla, dado que éstas han alcanzado la madurez suficiente
como para poderse emplear en múltiples aplicaciones.
III.1. Arquitectura del reconocedor
de habla natural
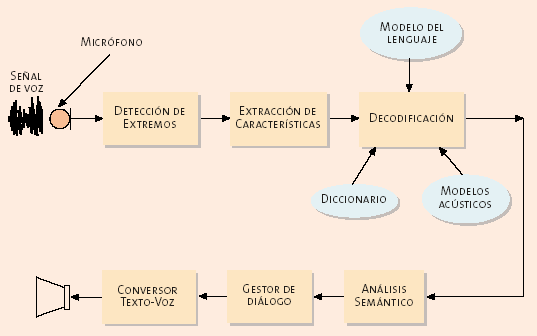
En la figura 1 se presenta el esquema típico
de un sistema de diálogo. En el proceso de reconocimiento se emplean cuatro
tipos de información:
1. Los modelos acústicos, que
permiten que el reconocedor identifique los sonidos, pues proporcionan información
sobre las propiedades y características de los mismos.
2. El diccionario, que indica
qué conjunto de sonidos forma cada palabra del vocabulario.
3. El modelo del lenguaje,
que tiene información de cómo se deben combinar las palabras para formar frases.
4. Los sistemas de diálogo o conversacionales,
en los que el reconocedor suele disponer de predicciones sobre el contenido
de la siguiente frase que pronunciará el locutor.
Así pues, el funcionamiento del sistema
de diálogo completo es el siguiente:
La señal de voz entra por el micrófono y se convierte
en una señal eléctrica analógica que es posteriormente digitalizada.
Esta señal pasa al detector de extremos, que es el encargado
de detectar la presencia de voz y de pasar dicha voz al siguiente bloque del
reconocedor.
El extractor de características calcula una serie de
parámetros de la señal de voz que tienen información relevante para el proceso
de reconocimiento.
Estos parámetros se pasan al decodificador, el cual
se apoya en los modelos acústicos, los modelos del lenguaje y el diccionario
para generar la frase reconocida.
Posteriormente, el analizador semántico extraerá el
significado de la frase, que será utilizado por el gestor del diálogo para,
en función del estado de la conversación, tomar la decisión más adecuada y hacer
una predicción sobre la siguiente interacción con el usuario.
Como el problema general del reconocimiento
de voz no está totalmente resuelto, existen muchos tipos de reconocedores especializados
en resolver problemas concretos. Por este motivo, no se pueden comparar dos
reconocedores si no están especializados en la misma tarea y, aún en este caso,
habrá que asegurar que las condiciones de la prueba son idénticas para ambos,
antes de pronunciarse sobre la calidad de cada uno de ellos: comparar dos reconocedores
sin tener en cuenta su especialización es como comparar un coche de carreras
con uno familiar. No hay uno mejor que otro, simplemente son distintos. Como
éste es un punto importante que da lugar a mucha confusión, a continuación se
presenta una clasificación de los sistemas de reconocimiento atendiendo a varios
criterios:
►Según el número de
locutores que pueden reconocer
Dependientes del locutor. Sólo reconocen la voz de la
persona para la que han sido entrenados.
Multilocutor. Reconocen la
voz de un conjunto pequeño de personas.
Independientes del locutor. Reconocen la voz de cualquier
persona.
Según el tamaño del vocabulario que reconocen
Reconocedores de vocabularios pequeños: hasta 40 palabras.
Reconocedores de vocabularios medios: hasta 400 palabras.
Reconocedores de vocabularios grandes: hasta 4.000 palabras.
Reconocedores de vocabularios muy grandes: hasta 40.000
palabras.
Reconocedores de vocabularios ilimitados: más de 40.000
palabras.
Según el canal
Reconocedores a través de micrófono.
Reconocedores para la red telefónica (fija, móvil analógica
o móvil digital).
Según el tiempo de respuesta
Reconocedores de tiempo real. Son reconocedores que
dan una respuesta lo suficientemente rápida como para que un usuario pueda interaccionar
con ellos.
Resto. Reconocedores en los que el tiempo de respuesta
no es un factor importante (por ejemplo, sistemas de reconocimiento empleados
para la transcripción de informes, reconocedores de
laboratorio para investigar nuevas técnicas de reconocimiento, etc.).
III.2. Características del reconocedor
de habla natural
La utilización de técnicas de reconocimiento
en servicios reales no es trivial, dado que todavía quedan algunos problemas
tecnológicos por resolver. Por tanto, es importante tener en cuenta estos factores
a la hora de diseñar un servicio, dado que el éxito del mismo depende, en gran
medida, del conocimiento de las tecnologías implicadas.
A continuación se describen las características
que afectan al funcionamiento de los reconocedores de voz.
►Independencia del
locutor
Los seres humanos percibimos las características
de las voces de las personas con gran facilidad. Esta capacidad nos permite
identificar a una persona por su voz o incluso conocer datos de la misma, como
la región en la que aprendió a hablar o en la que vive habitualmente, su nivel
cultural, sexo, edad, algunos rasgos de su forma de ser, su estado de ánimo,
etc. Por tanto, el conjunto de sonidos emitidos al hablar no sólo lleva la información
del mensaje contenido en la frase pronunciada, sino que también lleva información
sobre el interlocutor.
Toda esta información complementaria
al propio mensaje, lejos de dificultar la comprensión, ayuda a mejorar el proceso
de comunicación entre las personas. Sin embargo, en el caso de los sistemas
de reconocimiento, las diferencias entre distintas voces tienen efectos negativos
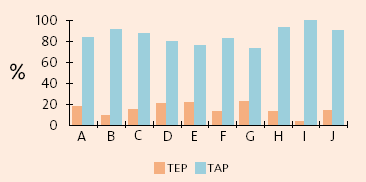
en la tasa de aciertos. En la figura 2 se ilustra este
hecho, y se muestran, para diez locutores distintos, las distintas tasas de
error de palabra (TEP) y de acierto de palabra (TAP) del reconocedor de habla
continua (versión de 1996).
El reconocedor fue evaluado dentro
del sistema de diálogo ATOS, sin que los usuarios supieran el vocabulario que
el sistema era capaz de reconocer, empleando frases de habla natural (sin restricciones)
para solicitar los casi 30 servicios distintos que proporcionaba esta primera
versión del sistema ATOS. El tamaño del vocabulario que manejaba el sistema
era de unas 2.000 palabras. Véase cómo la tasa de error para el locutor "I"
es prácticamente despreciable, mientras que la tasa de error del locutor "G"
es del 25 por ciento, por lo que mientras el locutor "I" estará muy
satisfecho con el servicio, el segundo (con un error por cada cuatro palabras)
tendrá la sensación de que el sistema no funciona.
Las diferencias en las tasas de error
se deben a que los modelos acústicos que maneja un reconocedor para poder realizar
el proceso de reconocimiento se obtienen, en el proceso de entrenamiento, a
partir de un conjunto finito de voces de muchas personas, de modo que:
El sistema no funcionará bien con aquellas voces que
sean muy distintas de las empleadas en el proceso de entrenamiento.
Los modelos acústicos modelan una voz "promedio",
resultado de procesar las voces del conjunto empleado para entrenar el sistema,
por lo que tampoco las voces parecidas a las de dicho conjunto se reconocen
con las tasas de error que se obtendrían si el sistema hubiera sido entrenado
para una sola persona.
Adicionalmente, en reconocimiento
de habla continua, el modelo del lenguaje, y el diccionario afectan también
a las tasas de reconocimiento: si la persona que utiliza el sistema pronuncia
frases que están bien modeladas por el modelo del lenguaje, y cuyas palabras
están incluidas en el diccionario, el reconocedor funcionará mejor que en el
caso contrario.
Por tanto, es necesario dotar a los
reconocedores de técnicas de adaptación al locutor que permitan que el sistema
pueda modificar dinámicamente los modelos acústicos, el diccionario y el modelo
del lenguaje, a fin de que la tasa de error sea la mínima posible e igual para
todos los posibles usuarios.
El problema de la adaptación al locutor
no es en absoluto trivial, dado que hay múltiples causas por las que dos voces
son distintas, y la forma en que cada una de estas causas afecta a la señal
de voz (y, por tanto, a sus parámetros) no es fácil de predecir de una forma
determinista en la mayoría de los casos. Igualmente, el problema de adaptar
el modelo del lenguaje, y de modificar dinámica y automáticamente el diccionario,
es complejo.
A continuación se presenta una clasificación
de las causas de la variabilidad de la voz, que sin pretender ser completa ni
totalmente precisa, sí da una idea de la complejidad del problema con que nos
enfrentamos. Las causas de la variabilidad se han dividido en tres grandes grupos:
1. Diferencias culturales
Se clasifican como diferencias culturales
a todas aquellas que han sido aprendidas por el individuo.
En este sentido, aparecen las siguientes:
Amplitud de los sonidos (volumen)
Conjunto de sonidos empleado
Duración de los sonidos
Entonación
Forma de construir las frases (¿Comiste?, en lugar de:
¿Has comido?)
Velocidad del habla
Vocabulario empleado, que está directamente relacionado
con el nivel cultural, el dialecto y el contexto (filosofía, medicina, ingeniería,
arte, deportes, etc.)
Cabe destacar que, en algunas ocasiones,
hay ciertos sonidos pronunciados por un locutor que pueden ayudar a predecir
la forma en la que va a pronunciar otras palabras. Por ejemplo, en la zona de
Madrid es típico pronunciar "es que" como /e j k e/, por lo cual,
si un locutor emplea esa pronunciación hará lo mismo con otras palabras en las
que el sonido /s/ preceda al sonido /k/: "escapar" se pronunciará
como /e j k a p a r/. La combinación de los factores anteriores da lugar a distintos
estilos del habla para un mismo locutor (claro, articulado, culto, vulgar
).
2. Diferencias fisiológicas
En este apartado se sitúan las diferencias
inherentes a la constitución física del locutor o a su estado físico o de salud
(cansancio, congestión nasal, afonía, frecuencia fundamental de las cuerdas
vocales
). Así, por ejemplo, la voz suele ser más lenta y forzada cuando el
locutor está cansado, o la congestión nasal afecta a la pronunciación de las
nasales, etc.
3. Diferencias de entorno
El entorno en el que está inmerso
el locutor influye, también, en las características de la voz. Por ejemplo,
pueden afectar a la voz:
El ruido de fondo, que hace que el esfuerzo realizado
por las cuerdas vocales sea mayor, lo que modifica el proceso de producción
de la voz. Este fenómeno se conoce con el nombre de efecto Lombard.
Los factores mecánicos como las vibraciones o aceleraciones.
Los estados emocionales del individuo (miedo, ira, enfado,
sorpresa, nerviosismo, estado de ánimo, etc.)
Tipo de entorno o de canal, desde el punto de vista
acústico: reverberante, distorsionador, etc.
►Efectos del canal
y del ruido
Numerosos experimentos realizados
demuestran que el ruido de fondo afecta relativamente poco a las tasas de reconocimiento
de los seres humanos y, por tanto, al proceso de comunicación. Esto se debe
fundamentalmente a tres factores:
1. Las personas tenemos dos oídos,
lo que nos permite la identificación de las fuentes de sonido y su separación,
gracias al procesado realizado posteriormente en el cerebro.
2. La capacidad de predicción del
cerebro, apoyándose en una serie de fuentes de conocimiento, como el propio
conocimiento del lenguaje de la persona o personas con las que se está hablando,
el contexto y tema de la conversación, etc.
3. La capacidad de adaptación del
cerebro, tanto al ruido cómo a la cancelación.
Estos factores hacen que los seres
humanos seamos claramente superiores a los reconocedores de voz, que hacen su
trabajo basándose en conocimiento acústico y en un modelo limitado del lenguaje.
Está claro, por tanto, que los sistemas de reconocimiento deberían emplear más
información para realizar su tarea, aunque no se sepa a ciencia cierta qué información
es, ni cómo utilizarla.
Desde el punto de vista del reconocimiento
de voz, ruido es cualquier señal acústica o eléctrica que contamine la señal
de voz que queremos reconocer. Atendiendo a esta definición, el ruido se puede
clasificar en tres grandes grupos:
1. Ruido estacionario. Dentro
de este grupo englobaríamos todos aquellos ruidos cuyas propiedades se mantienen
constantes a lo largo del tiempo o, al menos, en un periodo suficientemente
largo de tiempo. La característica fundamental de este grupo es que conocido
el ruido que hay en un periodo de tiempo, se puede predecir con bastante
exactitud el ruido que tendremos
en un instante de tiempo posterior. Como ejemplos de este tipo de ruido, tenemos
el ruido producido por los tubos fluorescentes, por los ventiladores de los
ordenadores, por un motor al ralentí, etc.
2. Ruido no estacionario. Agruparía
todos los ruidos que no entran en el apartado anterior. Esto es, ruidos impredecibles,
que están variando continuamente o que aparecen de forma intermitente sin ninguna
periodicidad. Desgraciadamente, la mayoría de los ruidos que existen en el mundo
real son de este tipo. Así, por ejemplo, el ruido del tráfico o el de una fábrica
pertenecen a este grupo.
3. Voces de fondo. Pertenecerían
estrictamente al segundo grupo. Se han puesto aparte por su efecto especialmente
dañino en los sistemas de reconocimiento. Las voces de fondo no sólo degradan
las tasas de reconocimiento, por contaminar la voz que el reconocedor está procesando,
sino que, en un momento dado, un servicio podría fallar por reconocer la voz
de fondo producida por un interlocutor distinto del usuario del servicio (aún
habiendo reconocido correctamente la frase pronunciada por dicho interlocutor).
En el caso de reconocimiento por línea
telefónica, el problema del ruido se agrava por la influencia del canal telefónico,
entendiéndose por canal el conjunto de todos los elementos que hay entre el
locutor y el reconocedor: el micrófono, la propia línea telefónica y los diversos
circuitos eléctricos y electrónicos por los que pasa la voz antes de llegar
al sistema de reconocimiento. En estos momentos, la creciente variedad de teléfonos
que se conectan a la red telefónica produce diversos efectos en la señal de
voz, que, en general, no son beneficiosos para el buen funcionamiento del reconocedor.
Igualmente, la codificación que se emplea tanto en telefonía móvil como en la
red IP modifica las propiedades de la señal de voz, introduciendo una variabilidad
que perjudica a las tasas de reconocimiento.
Existen diversas técnicas para atacar
los problemas del ruido estacionario y de ciertas distorsiones debidas a la
variabilidad del canal. Sin embargo, no se puede decir lo mismo del caso del
ruido no estacionario y de las voces de fondo, que siguen siendo problemas sin
resolver para el caso de reconocimiento por línea telefónica.
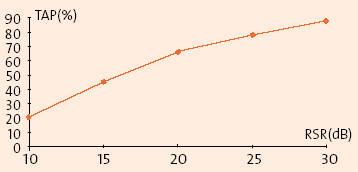
En la figura 3 se observa el efecto
del ruido estacionario en las tasas de reconocimiento de un reconocedor de palabras
aisladas por línea telefónica, cuyo vocabulario es de unas 500 palabras con
alto nivel de confusión. En la realización del experimento no se empleó ninguna
técnica de compensación de ruido. El eje de abscisas muestra la relación señal
a ruido (RSR). En el eje de ordenadas se presenta la tasa de acierto de palabras
(TAP). Como se puede observar, la tasa de error aumenta considerablemente cuando
la relación señal a ruido disminuye.
►Independencia del
dominio semántico
De todo lo visto hasta ahora, se desprende
que el reconocimiento de voz por línea telefónica se enfrenta con una serie
de dificultades que limitan seriamente las posibilidades de utilización de estas
tecnologías en servicios reales: por un lado, el problema de la independencia
del locutor, que no está totalmente resuelto. Por otro lado, está el problema
del canal y del ruido, que degrada las tasas de reconocimiento, tal y como se
ha visto en el apartado anterior. Dado que ninguno de estos problemas está totalmente
resuelto en la actualidad, es aconsejable "ayudar" al reconocedor
en el proceso de diseño de los servicios, por medio de las siguientes estrategias:
1. Reduciendo el vocabulario que maneja
el reconocedor de voz, a fin de disminuir la probabilidad de que confunda unas
palabras con otras, y eliminar ambigüedades (ya que una misma palabra puede
tener significados distintos en dos contextos diferentes).
2. Diseñando diálogos que guíen al
usuario para que diga las cosas en la forma en que el reconocedor está esperando.
3. Reestimando
los modelos del lenguaje tan pronto como se disponga de diálogos provenientes
del servicio real.
La reducción del vocabulario conlleva
la especialización del mismo en la tarea en la que se va a utilizar el reconocedor
y, consecuentemente, la especialización del modelo del lenguaje, de los modelos
acústicos, del diccionario y del módulo de procesamiento del lenguaje natural
(PLN): el modelo del lenguaje estará diseñado para que favorezca al máximo combinaciones
de palabras con sentido dentro del dominio de la tarea, los modelos acústicos
se habrán obtenido probablemente a partir de frases relacionadas con dicho dominio,
el diccionario estará compuesto únicamente por las palabras del vocabulario
y el módulo de PLN estará configurado por reglas que, incluso, podrán estar
metidas en el propio código y que estarán adaptadas al dominio en cuestión.
Así pues, si quisiéramos emplear el mismo reconocedor en una tarea distinta,
habría que cambiar el vocabulario y, con ello, los modelos del lenguaje, el
diccionario, los modelos acústicos y el módulo de PLN.
En la mayoría de los casos, cuando
se va a utilizar un sistema de reconocimiento para dar un nuevo servicio por
línea telefónica, no se conoce a priori el comportamiento de los usuarios al
encontrarse con un sistema automático, ni se sabe qué vocabulario ni qué tipo
de frases se van a emplear para comunicarse con el mismo. Por tanto, en la creación
de un nuevo servicio, hay que establecer una hipótesis de partida para poder
configurar un sistema inicial que, tras sucesivas pruebas de campo, va completándose
y adaptándose a la tarea para la que fue diseñado.
El problema es que mientras que el
diccionario y el módulo de PLN se pueden crear a partir de unas hipótesis de
trabajo, el modelo del lenguaje necesita de miles de frases para poder generar
un modelo que esté adaptado a la tarea. Esto es, que no podremos disponer del
mismo hasta que no se haya probado el sistema lo suficiente como para disponer
de dichas frases. En cuanto a los modelos acústicos, el problema es menor, dado
que existen técnicas que permiten predecir modelos a partir de los que ya están
generados, por lo que se puede disponer de unos modelos iniciales que funcionen
de una forma bastante satisfactoria. Adicionalmente, cada vez hay más bases
de datos de voz disponibles, por lo que es relativamente sencillo generar modelos
acústicos genéricos, que tengan un buen comportamiento en la mayoría de las
tareas.
►Características del
habla espontánea
Ésta es otra de las grandes cuestiones
con las que se enfrenta el reconocimiento de habla continua en los sistemas
reales. El habla espontánea o natural es el tipo de habla que empleamos los
seres humanos al comunicarnos entre nosotros y presenta una serie de problemas
con respecto a otros estilos de habla, como el habla leída, ya que no sigue
completamente la normativa. Este estilo de habla presenta las siguientes características:
Los sonidos aparecen pobremente articulados con relativa
frecuencia
Se coarticulan muchos sonidos
La velocidad del habla es variable
Suelen aparecer correcciones, falsos comienzos de frase
y sonidos guturales
No sigue estrictamente las reglas del lenguaje
Un mismo idioma puede tener multitud de acentos/dialectos.
Los efectos de todas estas características
en la señal de
voz son importantes, ya que:
1. Existen muchos sonidos que desaparecen
o que pierden parte de sus propiedades acústicas.
2. Hay sonidos que no pertenecen al
idioma "normativo", pero sí pertenecen a un determinado dialecto del
mismo.
3. Los modelos del lenguaje funcionan
peor que con el estilo de habla leído, ya que las correcciones, falsos comienzos
y sonidos guturales, junto con la falta de gramaticalidad de algunas frases,
reducen la capacidad de corrección del modelo del lenguaje.
Los tres problemas descritos constituyen
los principales retos que tiene la tecnología de reconocimiento de voz en nuestros
días. Las soluciones de estas cuestiones, lejos de ser responsabilidad de una
única disciplina de la ciencia, se alcanzarán como resultado de la sinergia
de múltiples áreas de conocimiento, y precisarán de ordenadores mucho más potentes
que los actuales. Quedan todavía muchos experimentos por hacer, y muchas cosas
por comprender, antes de llegar a soluciones definitivas, pero también es cierto
que los medios con que contamos actualmente, junto con el elevado número de
personas que están investigando en este tema, hacen que podamos mirar hacia
el futuro con optimismo. Ya existen muchos servicios que pueden automatizarse
con la tecnología existente, y las mejoras incrementales, que se producen de
forma continuada cada año, van permitiendo el desarrollo de sistemas más complejos,
que hacen posible la puesta en marcha de servicios cada vez más sofisticados.
III.3. Procedimiento de reconocer
voz
Los sistemas de reconocimiento
de voz se enfocan en las palabras y los sonidos que distinguen una palabra de
la otra en un idioma, los fonemas. Por ejemplo, "losa", "cosa"
y "posa" son palabras diferentes puesto que su sonido inicial se reconocen
como fonemas diferentes en Español.
Existen varias maneras
para analizar y describir el habla. Los enfoques más comúnmente usados son:
1. Articulación:
Análisis de cómo el humano produce los sonidos del habla. Aquí cabría citar el sistema de
generación de voz del ser humano (cuerdas vocales, boca, nariz
) y los diferentes
fonemas que se pueden generar a través del mismo.
2. Acústica: Análisis de la
señal de voz
como una secuencia de sonidos. Dentro de este campo cabe tener en cuenta la
frecuencia, la amplitud, el nivel de ruido
De especial importancia es tener
en cuenta la frecuencia fundamental, pues el habla, como casi cualquier sonido,
es un tono de una frecuencia determinada (la llamada fundamental) combinado con una serie de frecuencias secundarias. Algunas
bandas de la frecuencia secundarias juegan un rol importante en la distinción
de un fonema de otro; se les llama formantes y son producidas por la resonancia.
La garganta, la boca y la nariz son cámaras de resonancia que amplifican las
bandas o frecuencias formantes contenidas en el sonido generado por las cuerdas
vocales. Estas formantes amplificadas dependen del tamaño y forma de la boca
y si el aire pasa o no por la nariz. Los patrones de las formantes son más fuertes
(distinguibles) para vocales que para las consonantes no sonoras.
La cuestión es que
el habla no es un tono puro, sino que es un conjunto de múltiples frecuencias
y se representa como una onda compleja. Por ejemplo, las vocales se componen
de 2 o más ondas simples y son ricas en frecuencias secundarias y contienen
estructuras internas que incluyen ondas cíclicas y acíclicas.
Todas estas particularidades
de cada sonido se analizan utilizando técnicas como la transformada rápida de
Fourier (FFT), generando mediante la
misma espectrogramas. Un ejemplo de espectrograma podría ser el que aparece
en la figura 4.
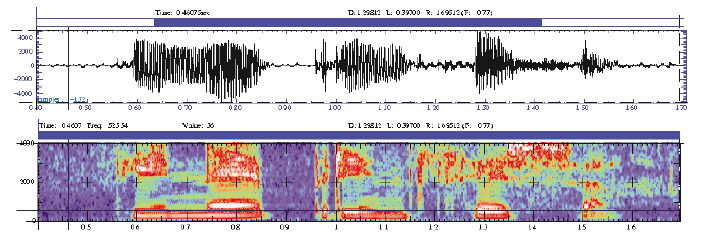
Figura
4: Forma de onda y espectrograma
Pero
aun teniendo todo esto, el problema más grave es que cada fonema no es un sonido
aislado, sino que digamos que un fonema es una abstracción, pues cada fonema
va a depender mucho de los distintos fonemas que van antes y después, pronunciándose
de diferente manera según los mismos.
3. Percepción
auditiva: el oído
humano, junto con el cerebro, conforman un sistema de percepción desconocido
aún. Se sabe el rango de frecuencias que es capaz de escuchar el oído, y su
carácter no lineal, por lo cual en el reconocedor de hablas se intenta emplear
un filtro similar.
Una vez decepcionada
la señal auditiva, se ha de digitalizar, mediante el tradicional método de muestreo
y cuantificación, empleo de señales PAM-PCM y una de las numerosas técnicas
de codificación (Millar, Manchester, Manchester diferencial
). Por
último, para traducir la señal obtenida a texto, se basa en una serie de comparaciones
con una base de datos de sonidos ya preconcebidos. La decisión de optar por
una palabra determinada se hace mediante el algoritmo de Viterbi
(algoritmo que, muy básicamente, da como resultado la palabra de la base de
datos que menor número de diferencias tiene con respecto a la que estábamos
comparando).