Cuando el oído está expuesto a 2 o más sonidos simultáneos, existe la posibilidad de que uno de ellos enmascare a los demás. Cabe definirlo como un efecto producido en la percepción sonora cuando se escuchan dos sonidos de diferente intensidad al mismo tiempo. Al suceder esto el sonido más débil resultará inaudible, ya que el cerebro sólo procesará el sonido enmascarador.
El sonido de nivel más alto tendrá un efecto enmascarador mayor si el suave tiene una frecuencia cercana a la suya.
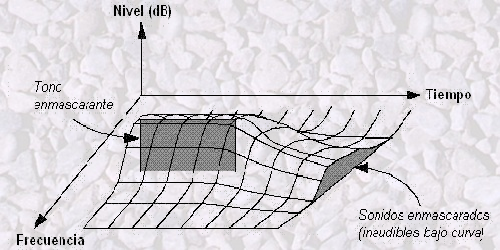
Se puede dividir el enmascaramiento sonoro en enmascaramiento temporal y enmascaramiento frecuencial.
(Fuente de todas las audiciones http://www.ece.uvic.ca/~aupward/p/demos.htm)
El enmascaramiento temporal sucede cuando dos estímulos sonoros llegan a nuestro oído de forma cercana en el tiempo. El estímulo enmascarante hará que el otro, enmascarado, resulte inaudible. Dada esta situación, el tono más intenso tiende a enmascarar el tono más débil.
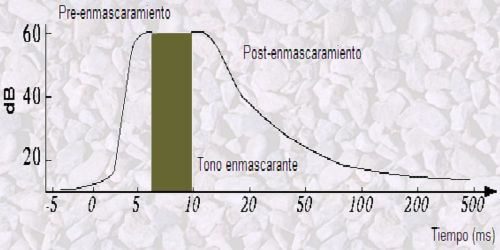
Según el instante de tiempo en el que se produce el estímulo enmascarante con respecto al instante en que se produce el enmascarado, se puede distinguir entre Post-enmascaramiento y Pre-enmascaramiento.
Post-enmascaramiento:
Se da cuando es el tono de mayor amplitud el que sucede con antelación en el tiempo al de menor amplitud, percibiéndose tan sólo el primer estímulo. Este fenómeno se produce cuando ambos sonidos llegan al oído en un intervalo de tiempo de entre 30 y 60 ms aproximadamente. Esto se debe a que una vez percibido el tono fuerte, el oído necesita un cierto periodo de adaptación.
Ejemplo 1. Los tonos están separados por 100 ms y no se aprecia enmascaramiento ni siquiera tras reducir el tono menor en 3 dB.
Si se produce primero un estímulo suave y posteriormente un tono intenso, este último enmascarará igualmente al de menor amplitud, siempre cuando estén separados en el tiempo por una diferencia menor de entre 5 y 10 ms. Como este fenómeno se presenta incluso antes de que aparezca el tono enmascarante, implica que se trata de un proceso más complejo que el Post-enmascaramiento.
La explicación a esta anticipación se encuentra en que la información que llega a la corteza auditiva del cerebro humano se procesa por ráfagas. Así mismo se sabe que el cerebro procesa los sonidos fuertes más rápido que los débiles, facilitándose de esta forma el pre-enmascaramiento.
Por otro lado, un ejemplo práctico es el de la continuidad de los tonos, una ilusión auditiva por la que, reproduciéndose un tono ininterrumpidamente, el oyente lo percibe como continuo.
El enmascaramiento frecuencial es la disminución de la sonoridad de un tono a una cierta frecuencia, en presencia de otro tono simultáneo a una frecuencia diferente. Es decir, cuando el oído es expuesto a dos o más sonidos de diversas frecuencias, existe la posibilidad de que uno de ellos camufle a los demás y, por tanto, que éstos no se oigan.
Se presenta cuando dos tonos llegan al oído simultáneamente quedando uno de ellos enmascarado por el otro. Se pueden dar dos casos:
- Sonidos de baja frecuencia enmascaran a los de alta frecuencia.
- Sonido de alta frecuencia enmascaran a los de baja frecuencia.
Es importante señalar que en el enmascaramiento en frecuencia será más efectivo en el primer caso, ya que los tonos de alta frecuencia difícilmente enmascaran a los de una frecuencia menor.
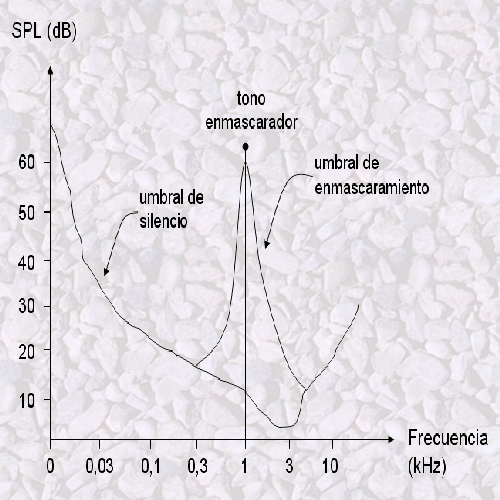
En psicoacústica, el umbral de enmascaramiento es el nivel de presión sonora (SLP) de un sonido de prueba necesario para que éste sea apenas audible en presencia de una señal enmascarante. Este nivel depende también en gran medida de la frecuencia y de las características del enmascarado y del enmascarador. El efecto aparece normalmente entre tonos muy cercanos en frecuencia.
Que no sea audible implica ciertas ventajas en el mundo de las transmisiones. En cuanto a codificación de audio, por ejemplo, implica la posibilidad de pasar por alto dicho tono consiguiendo así una mejor compresión ó, en su alternativa, la codificación con menos peso, es decir, menos bits y por consiguiente reducir el tamaño del fichero resultante.
Habitualmente no se trabaja con un solo tono sino con varios de forma simultánea. Así que para una sola frecuencia se tienen más de una posible señal enmascaradora. Para estas situaciones se calcula el que se conoce como umbral de enmascaramiento global. Éste se cuantifica en base a un espectro de alta resolución de la señal (habitualmente de audio) a partir de una Transformada rápida de Fourier (FFT) de 512 ó 1024 puntos. En primera instancia se calculan los umbrales individuales teniendo en cuenta el nivel de señal, el tipo de enmascarador (ya sea señal ó ruido) y la banda de frecuencias (hay frecuencias inaudibles para el oído humano). Posteriormente se suman todos los umbrales añadiéndose el umbral de tranquilidad, de esta forma se asegura que el umbral de enmascaramiento total no estará nunca por debajo de este último. Finalmente se puede calcular el SMR (Signal to Mask Ratio). La anterior operación es la que se lleva a cabo en codificación de audio.
En el siguiente gráfico se muestra el caso de tener un tono a 1kHz. Se puede observar el umbral de tranquilidad o silencio debajo del cual ningún sonido es perceptible. Ahora bien, al sobreponer el tono este nivel varia alrededor de la frecuencia central del enmascarador haciendo más difícil oír las posibles frecuencias cercanas a éste.
Una aplicación del umbral de enmascaramiento la encontramos en las codificaciones de audio que usa MPEG. En estos esquemas se incluye el bloque denominado 'modelo psicoacústico'. Éste está comunicado con el banco de filtros y el bloque de cuantificación (ó asignación de bits). El modelo psicoacústico es el encargado de analizar las muestras que provienen del banco de filtros calculando, para cada banda, el nivel de enmascaramiento. El procedimiento, como ya se ha comentado en el párrafo anterior, se lleva a cabo mediante un FFT. Según la capa de MPEG en la que estemos trabajando se utilizan más o menos puntos. A partir de todos los distintos niveles se calcula el SMR que se pasa al cuanitificador. El cuantificador es el encargado de asignar más o menos bits a cada uno de los bloques frecuenciales teniendo en cuenta el SMR. El bloque con máxima relación señal-enmascaramiento se codificará con el máximo de bits posible mientras que el que tenga la peor relación con el mínimo, llegando a ser cero bits.
En definitiva, el cálculo del umbral de enmascaramiento es tenido en cuenta por ciertos códecs de audio con tal de no codificar muestras que, al fin y al cabo, si se codificaran, serian igualmente inaudibles para el oído humano. De este modo se utilizan menos bits y en consecuencia se reduce el tamaño del archivo de audio consiguiendo así una mejor compresión